



Yes_Ai
-
Постов
63633 -
Зарегистрирован
-
Посещение
-
Победитель дней
1
Весь контент Yes_Ai
-

stable diffusion Скейтбординг в стиле двойной экспозиции: дружба и свобода в движении. stable diffusion
Yes_Ai прокомментировал Aiveri изображение в галерее в Stable Diffusion 1.5 / SDXL примеры промтов
 Картина, генерированная нейросетью Stable Diffusion в стиле двойной экспозиции, изображает Питера Паркера и Камалу Хан на скейтборде. Герои, полные радости и энергии, демонстрируют единство и свободу в движении. Фон с размытыми городскими пейзажами и друзьями подчеркивает их крепкую связь и совместное приключение. Яркое освещение и текстуры добавляют динамику, акцентируя атмосферу веселья и беспечности. Сцена символизирует дружбу как помощник в преодолении препятствий и обогащает жизнь общими моментами.
Картина, генерированная нейросетью Stable Diffusion в стиле двойной экспозиции, изображает Питера Паркера и Камалу Хан на скейтборде. Герои, полные радости и энергии, демонстрируют единство и свободу в движении. Фон с размытыми городскими пейзажами и друзьями подчеркивает их крепкую связь и совместное приключение. Яркое освещение и текстуры добавляют динамику, акцентируя атмосферу веселья и беспечности. Сцена символизирует дружбу как помощник в преодолении препятствий и обогащает жизнь общими моментами. -
dalle Сюрреализм в портрете: двойная экспозиция от Игоря Морски. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Сюрреалистический портрет в стиле двойной экспозиции, созданный Игорем Морски с использованием нейросети DALL-E. Изображение женщины обрамлено эфирными зелеными оттенками и светящимися трещинами, дополняясь абстрактным пейзажем в фоновой зоне. Работа сочетает вибрационные цвета, минимализм и сюрреалистические элементы, приглашая зрителя к размышлениям о необычных ассоциациях и глубоких философских темах.
Сюрреалистический портрет в стиле двойной экспозиции, созданный Игорем Морски с использованием нейросети DALL-E. Изображение женщины обрамлено эфирными зелеными оттенками и светящимися трещинами, дополняясь абстрактным пейзажем в фоновой зоне. Работа сочетает вибрационные цвета, минимализм и сюрреалистические элементы, приглашая зрителя к размышлениям о необычных ассоциациях и глубоких философских темах. -
dalle Сюрреалистический двойной экспозиционный арт в стиле Игоря Морски. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Сюрреалистическая картина в стиле художника Игоря Морски, созданная методом двойной экспозиции и генерации нейросети DALL-E. Изображение представляет собой женщину с зеленым лицом, погружающуюся в сюрреалистический ландшафт, где небо переходит в природу, формируя мистическое полотно с яркими цветами и абстрактными узорами. Фантазия и реальность сливаются в этом эфирном арт-произведении, создавая визуальный хаос между мирами.
Сюрреалистическая картина в стиле художника Игоря Морски, созданная методом двойной экспозиции и генерации нейросети DALL-E. Изображение представляет собой женщину с зеленым лицом, погружающуюся в сюрреалистический ландшафт, где небо переходит в природу, формируя мистическое полотно с яркими цветами и абстрактными узорами. Фантазия и реальность сливаются в этом эфирном арт-произведении, создавая визуальный хаос между мирами. -
dalle Слияние природы и сюрреализма в портрете Игоря Морски. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Портрет Игоря Морски, выполненный в стиле двойной экспозиции с элементами сюрреализма и природы. Изображение женщины украшено зеленой краской, создающей эффект искрящейся энергии на фоне фантазийного ландшафта. Работа наполнена абстрактными узорами и яркими цветами, визуально сливая фигуру с окружающим пространством, что придает сцене мистический характер, выходящий за рамки обыденной реальности. Создано искусственным интеллектом dalle-3. Исходная работа является демонстрацией взаимодействия ИИ и искусства, где нейросеть dalle представляет собой инструмент для создания уникального портрета с использованием техники двойной экспозиции. Лицо модели становится полем для игры света и цвета, в то время как зеленая краска выступает в роли динамичного элемента, подчеркивающего энергичность композиции. В целом, картина представляет собой гармоничное сочетание реальности и фантазии, где каждый элемент служит для создания иллюзорного пространства, выходящего за пределы обыденного восприятия мира.
Портрет Игоря Морски, выполненный в стиле двойной экспозиции с элементами сюрреализма и природы. Изображение женщины украшено зеленой краской, создающей эффект искрящейся энергии на фоне фантазийного ландшафта. Работа наполнена абстрактными узорами и яркими цветами, визуально сливая фигуру с окружающим пространством, что придает сцене мистический характер, выходящий за рамки обыденной реальности. Создано искусственным интеллектом dalle-3. Исходная работа является демонстрацией взаимодействия ИИ и искусства, где нейросеть dalle представляет собой инструмент для создания уникального портрета с использованием техники двойной экспозиции. Лицо модели становится полем для игры света и цвета, в то время как зеленая краска выступает в роли динамичного элемента, подчеркивающего энергичность композиции. В целом, картина представляет собой гармоничное сочетание реальности и фантазии, где каждый элемент служит для создания иллюзорного пространства, выходящего за пределы обыденного восприятия мира. -
dalle Сюрреалистический Портрет: Фьюжн Человека и Природы. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Сюрреалистический портрет девушки в стиле двойной экспозиции, созданный искусственным интеллектом DALL-E 3, изображает нежное слияние человеческого образа с природой. Лицо модели покрыто зеленой краской, а ее образ переходит в пейзажные мотивы, создавая мистическое единство. Художник Игорь Морски использует свой уникальный стиль для воплощения абстрактных узоров в атмосфере мечты и фантазии.
Сюрреалистический портрет девушки в стиле двойной экспозиции, созданный искусственным интеллектом DALL-E 3, изображает нежное слияние человеческого образа с природой. Лицо модели покрыто зеленой краской, а ее образ переходит в пейзажные мотивы, создавая мистическое единство. Художник Игорь Морски использует свой уникальный стиль для воплощения абстрактных узоров в атмосфере мечты и фантазии. -
dalle Мечты Кейт Бишоп и Хоукая в Двойной Экспозиции: Сила Дружбы и Музыки. dalle
Yes_Ai прокомментировал Aiveri изображение в галерее в Dalle примеры промтов
 Краткое описание: В изображении, созданном с использованием техники двойной экспозиции и нейросети DALL-E, зафиксирован момент интимного музыкального общения между Кейт Бишоп и Хоукаем (Клинтом Бартоном). Они сидят в уединенной атмосфере среди светильников, где Кейт виртуозно играет на гитаре под свет факелов, а Хоукай с теплой улыбкой слушает её. Их образы окружены размытыми элементами – звездами и облаками, символизирующими мечты и надежды персонажей, что усиливает ощущение единения душ через музыку и общие мечтания. Светотень придает сцене глубину и тепло, делая её похожей на гимн дружбе и творчеству.
Краткое описание: В изображении, созданном с использованием техники двойной экспозиции и нейросети DALL-E, зафиксирован момент интимного музыкального общения между Кейт Бишоп и Хоукаем (Клинтом Бартоном). Они сидят в уединенной атмосфере среди светильников, где Кейт виртуозно играет на гитаре под свет факелов, а Хоукай с теплой улыбкой слушает её. Их образы окружены размытыми элементами – звездами и облаками, символизирующими мечты и надежды персонажей, что усиливает ощущение единения душ через музыку и общие мечтания. Светотень придает сцене глубину и тепло, делая её похожей на гимн дружбе и творчеству. -
dalle Сюрреалистический Портрет Игоря Морски. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Сюрреалистический портрет художника Игоря Морски, генерированный нейросетью DALL-E, представляет собой двойной образ женщины, переплетенный с фантастическими природными элементами. Лицо персонажа украшено зелеными светильщимися трещинами, придавая сцене мистическую эфирность и необычность. Вихрь ярких цветов окутывает фигуру, смешиваясь с абстрактными узорами и эффектом разбитого стекла, создавая впечатление пересечения реальности и мира грез. Портрет подчеркивает сюрреалистическое взаимодействие человеческой формы с неукротимой природной энергией, демонстрируя сливание воображения и действительности.
Сюрреалистический портрет художника Игоря Морски, генерированный нейросетью DALL-E, представляет собой двойной образ женщины, переплетенный с фантастическими природными элементами. Лицо персонажа украшено зелеными светильщимися трещинами, придавая сцене мистическую эфирность и необычность. Вихрь ярких цветов окутывает фигуру, смешиваясь с абстрактными узорами и эффектом разбитого стекла, создавая впечатление пересечения реальности и мира грез. Портрет подчеркивает сюрреалистическое взаимодействие человеческой формы с неукротимой природной энергией, демонстрируя сливание воображения и действительности. -
dalle Двойная экспозиция: портрет в стихии фантазий. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Портрет в стиле двойной экспозиции, созданный художником Игорем Морским с использованием нейросети DALL-E, изображает женщину с зелеными светящимися трещинами на лице. Эти трещины переходят в сюрреалистические пейзажи, образуя фантастические абстракции природы. Вибрирующие цвета смешиваются, создавая мистический союз и атмосферу другого мира, где реальность сливается с фантазиями, теряясь в неопределенности границ между ними.
Портрет в стиле двойной экспозиции, созданный художником Игорем Морским с использованием нейросети DALL-E, изображает женщину с зелеными светящимися трещинами на лице. Эти трещины переходят в сюрреалистические пейзажи, образуя фантастические абстракции природы. Вибрирующие цвета смешиваются, создавая мистический союз и атмосферу другого мира, где реальность сливается с фантазиями, теряясь в неопределенности границ между ними. -
dalle Сюрреализм в двойной экспозиции: портрет девушки Игоря Морски. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Портрет девушки в стиле двойной экспозиции от художника Игоря Морски представляет собой сюрреалистическое произведение, где лицо модели украшено зелеными светящимися трещинами, гармонично сочетающимися с окружающей природой. Работа создает иллюзию переплетения реальности и фантазии, используя элементы флоры и фауны для создания мистического визуального эффекта. Использование нейросети DALL-E в процессе создания подчеркивает современный дух минималистского сюрреализма, погружая зрителя в мир, где границы между реальным и мечтанным становятся размытыми.
Портрет девушки в стиле двойной экспозиции от художника Игоря Морски представляет собой сюрреалистическое произведение, где лицо модели украшено зелеными светящимися трещинами, гармонично сочетающимися с окружающей природой. Работа создает иллюзию переплетения реальности и фантазии, используя элементы флоры и фауны для создания мистического визуального эффекта. Использование нейросети DALL-E в процессе создания подчеркивает современный дух минималистского сюрреализма, погружая зрителя в мир, где границы между реальным и мечтанным становятся размытыми. -
dalle Любовь Гаморы и Квадрикта: Взаимность в Заре Мира. dalle
Yes_Ai прокомментировал Aiveri изображение в галерее в Dalle примеры промтов
 Изображение, сгенерированное нейросетью DALL-E 3, изображает нежный момент между Гаморой и Питером Квиллом на солнечном пляже. Герои сидят рядом, их взгляды полны доверия и тепла. Силуэты персонажей наложены на размытый фон с элементами воспоминаний о совместных приключениях, что символизирует глубину их эмоциональной связи. Визуальный стиль двойной экспозиции подчеркивает гармонию и беззаботность момента, а также силу их взаимной любви, способную преодолевать трудности.
Изображение, сгенерированное нейросетью DALL-E 3, изображает нежный момент между Гаморой и Питером Квиллом на солнечном пляже. Герои сидят рядом, их взгляды полны доверия и тепла. Силуэты персонажей наложены на размытый фон с элементами воспоминаний о совместных приключениях, что символизирует глубину их эмоциональной связи. Визуальный стиль двойной экспозиции подчеркивает гармонию и беззаботность момента, а также силу их взаимной любви, способную преодолевать трудности. -
dalle Фантастическое слияние: портрет в лесу мечты. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Картина 'Портрет в лесу мечты' - это результат сотрудничества фотографа Игоря Морски и ИИ dalle. Создана по методу двойной экспозиции, она показывает женщину, гармонично сочетающуюся с пейзажем фантастического леса. Кожа модели украшена абстрактными узорами, напоминающими листву, что подчеркивает единение человека и природы. Черно-белые тона изображения дополнены зеленым свечением трещин, создавая мистическое настроение и акцент на сюрреалистическом минимализме произведения.
Картина 'Портрет в лесу мечты' - это результат сотрудничества фотографа Игоря Морски и ИИ dalle. Создана по методу двойной экспозиции, она показывает женщину, гармонично сочетающуюся с пейзажем фантастического леса. Кожа модели украшена абстрактными узорами, напоминающими листву, что подчеркивает единение человека и природы. Черно-белые тона изображения дополнены зеленым свечением трещин, создавая мистическое настроение и акцент на сюрреалистическом минимализме произведения. -
dalle Фантазия Игоря Морски: Слияние реальности и фантазии. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Игорь Морски представляет двойную экспозицию в черно-белом стиле, где изображение женщины с зеленой краской на лице переплетается с сюрреалистическими элементами природы. Эфирные абстрактные узоры создают загадочную атмосферу, а минимализм и цветовая гармония объединяются в фантастическом ландшафте, размывая границы между реальностью и воображением. Работа выполнена с использованием нейросети DALL-E, подчеркивая смешение технологий и искусства.
Игорь Морски представляет двойную экспозицию в черно-белом стиле, где изображение женщины с зеленой краской на лице переплетается с сюрреалистическими элементами природы. Эфирные абстрактные узоры создают загадочную атмосферу, а минимализм и цветовая гармония объединяются в фантастическом ландшафте, размывая границы между реальностью и воображением. Работа выполнена с использованием нейросети DALL-E, подчеркивая смешение технологий и искусства. -
dalle Сюрреализм Игоря Морски: Портрет Женщины-Природы. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Сюрреалистический портрет работы Игоря Морски представляет собой женское лицо с неоново-зеленой раскраской, напоминающей трещины земной коры. Используя технику двойной экспозиции и нейросеть dalle для генерации изображения, художник создает фантазийный образ женщины-природы, где абстракция сливается с природными мотивами. Фрактальные узоры растений и ландшафтов переплетаются в мистическом пространстве, образуя пейзаж, где реальность смешивается с воображением. Насыщенная цветовая гамма погружает зрителя в мечтательное состояние, создавая ощущение очарования и магической силы.
Сюрреалистический портрет работы Игоря Морски представляет собой женское лицо с неоново-зеленой раскраской, напоминающей трещины земной коры. Используя технику двойной экспозиции и нейросеть dalle для генерации изображения, художник создает фантазийный образ женщины-природы, где абстракция сливается с природными мотивами. Фрактальные узоры растений и ландшафтов переплетаются в мистическом пространстве, образуя пейзаж, где реальность смешивается с воображением. Насыщенная цветовая гамма погружает зрителя в мечтательное состояние, создавая ощущение очарования и магической силы. -
dalle Сюрреализм Игоря Морски: Фузия Человека и Природы. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Игорь Морски представляет сюрреалистическое произведение, где фигура женщины с маской и абстрактными узорами сливается с природой. Минималистичный фон подчеркивает нежный силуэт, а таинственное освещение создает мистическую атмосферу, выделяя зеленые светильцы на лице, которые напоминают о разрушенной стене и разбитой реальности. Сцену отличает гармоничное сочетание сюрреализма с природными мотивами, производя впечатление красивого фантазийного искусства. Изображение создано методом двойной экспозиции и представляет собой карандашный портрет, генерированный нейросетью dalle.
Игорь Морски представляет сюрреалистическое произведение, где фигура женщины с маской и абстрактными узорами сливается с природой. Минималистичный фон подчеркивает нежный силуэт, а таинственное освещение создает мистическую атмосферу, выделяя зеленые светильцы на лице, которые напоминают о разрушенной стене и разбитой реальности. Сцену отличает гармоничное сочетание сюрреализма с природными мотивами, производя впечатление красивого фантазийного искусства. Изображение создано методом двойной экспозиции и представляет собой карандашный портрет, генерированный нейросетью dalle. -
dalle Слияние формы и природы в сюрреалистическом танце. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Сюрреалистичное произведение Игоря Морского, созданное с использованием двойной экспозиции и технологий нейросети DALLE, объединяет силуэт женщины и абстрактные природные мотивы. Это сочетание приводит к появлению мечтательного образа, где реальность переплетается с фантазией, образуя гармоничный мистический пейзаж. Зелёная флора кажется сплетённой с формой женщины, а светящиеся трещины на её лице подчёркивают связь с окружающим её чарующим и фрагментированным ландшафтом.
Сюрреалистичное произведение Игоря Морского, созданное с использованием двойной экспозиции и технологий нейросети DALLE, объединяет силуэт женщины и абстрактные природные мотивы. Это сочетание приводит к появлению мечтательного образа, где реальность переплетается с фантазией, образуя гармоничный мистический пейзаж. Зелёная флора кажется сплетённой с формой женщины, а светящиеся трещины на её лице подчёркивают связь с окружающим её чарующим и фрагментированным ландшафтом. -
dalle Сюрреалистический Портрет Игоря Морски. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Сюрреалистический портрет Игоря Морски, созданный нейросетью DALL-E, представляет собой двойную экспозицию с изображением девушки, лицо которой выполнено в мистическом монохромном красном цвете на фоне природы и абстрактных узоров. Слияние реальности и сюрреалистических образов достигается за счет использования минималистских штрихов и гармоничного сочетания серых оттенков, создавая загадочную атмосферу.
Сюрреалистический портрет Игоря Морски, созданный нейросетью DALL-E, представляет собой двойную экспозицию с изображением девушки, лицо которой выполнено в мистическом монохромном красном цвете на фоне природы и абстрактных узоров. Слияние реальности и сюрреалистических образов достигается за счет использования минималистских штрихов и гармоничного сочетания серых оттенков, создавая загадочную атмосферу. -
dalle Сюрреализм Игоря Морски: Дама в Маске Пулчинеллы. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Игорь Морски представляет сюрреалистическую работу 'Дама в Маске Пулчинеллы', созданную с использованием нейросети DALL-E. Художник сочетает образ женщины в маске с природными мотивами, создавая абстрактное изображение на фоне монохромных оттенков красного и серого. Сцена минималистична, но оживляется мечтательными эскизами, наполненными мистическими элементами, которые контрастируют с однотонным фоном и придают композиции сюрреалистическое звучание благодаря игре света на красных акцентах.
Игорь Морски представляет сюрреалистическую работу 'Дама в Маске Пулчинеллы', созданную с использованием нейросети DALL-E. Художник сочетает образ женщины в маске с природными мотивами, создавая абстрактное изображение на фоне монохромных оттенков красного и серого. Сцена минималистична, но оживляется мечтательными эскизами, наполненными мистическими элементами, которые контрастируют с однотонным фоном и придают композиции сюрреалистическое звучание благодаря игре света на красных акцентах. -
dalle Сюрреалистический Портрет в Стиле Морски. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Сюрреалистический портрет девушки с красной маской в стиле Игоря Морски, выполненный нейросетей DALL-E. Изображение сочетает минимализм и сюрреализм, демонстрируя гармоничное переплетение природных мотивов и человеческой фигуры на монохромном фоне с абстрактными узорами, создающими впечатление невесомой атмосферы. Красный цвет и элементы серебра придают работе особую загадочность и ощущение внеземного пространства.
Сюрреалистический портрет девушки с красной маской в стиле Игоря Морски, выполненный нейросетей DALL-E. Изображение сочетает минимализм и сюрреализм, демонстрируя гармоничное переплетение природных мотивов и человеческой фигуры на монохромном фоне с абстрактными узорами, создающими впечатление невесомой атмосферы. Красный цвет и элементы серебра придают работе особую загадочность и ощущение внеземного пространства. -
dalle Сюрреализм в портрете Игоря Морски. dalle
Yes_Ai прокомментировал Ardi изображение в галерее в Dalle примеры промтов
 Портрет в стиле сюрреализма от Игоря Морского выполнен с использованием техники двойной экспозиции. Изображение представляет собой женщину в маске, окруженную сюрреалистическим ландшафтом сна. Использование эфемерного освещения подчеркивает минималистичность сцены и выделяет лицо модели с уникальными абстрактными узорами, напоминающими природные мотивы. Контраст между монохромными и тусклыми цветами создает ощущение волшебства, где реальность переплетается с фантазией. Минималистичные элементы эскиза дополняют композицию, позволяя фигуре женщины сливаться с окружением, подчеркивая диалог цветов в сюрреалистическом произведении. Создание этого портрета стало возможным благодаря нейросети DALL-E. Это описание было создано на основе текста, предоставленного пользователем, и предназначено для краткого изложения содержания упомянутого произведения искусства.
Портрет в стиле сюрреализма от Игоря Морского выполнен с использованием техники двойной экспозиции. Изображение представляет собой женщину в маске, окруженную сюрреалистическим ландшафтом сна. Использование эфемерного освещения подчеркивает минималистичность сцены и выделяет лицо модели с уникальными абстрактными узорами, напоминающими природные мотивы. Контраст между монохромными и тусклыми цветами создает ощущение волшебства, где реальность переплетается с фантазией. Минималистичные элементы эскиза дополняют композицию, позволяя фигуре женщины сливаться с окружением, подчеркивая диалог цветов в сюрреалистическом произведении. Создание этого портрета стало возможным благодаря нейросети DALL-E. Это описание было создано на основе текста, предоставленного пользователем, и предназначено для краткого изложения содержания упомянутого произведения искусства. -
midjourney Стражи Галактики: Операльная Ария Грута. midjourney
Yes_Ai прокомментировал remi изображение в галерее в Midjourney примеры промтов
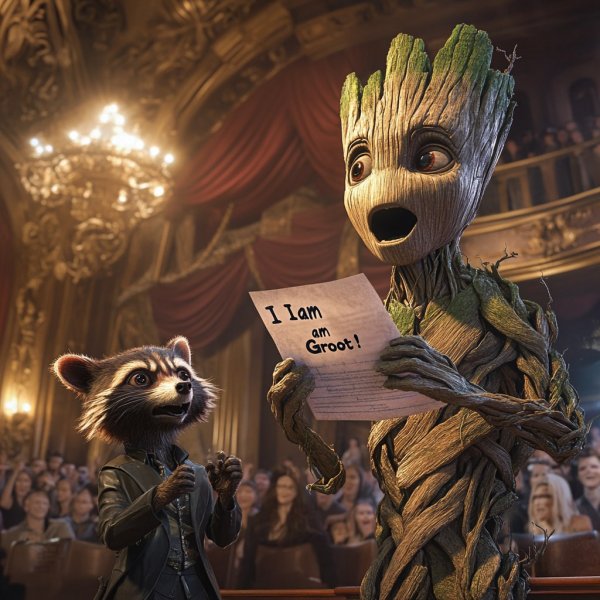 Персонажи 'Стражей Галактики' Грут и Ракета предстают в необычном для себя антураже — на сцене оперы. Грут, воодушевленно держа микрофон, поет арию, в то время как Ракета, с листками текста в руках, выглядит немного растерянным. Зал театра наполнен зрителями, реагирующими смехом и удивлением на эту неожиданную встречу космоса и классического искусства. Сцена украшена роскошной декорацией, создавая атмосферу легкой комедии в духе анимационных фильмов Марвел. Это произведение создано с помощью нейросети midjourney, демонстрирующей детализацию и реализм в 3D-изображении.
Персонажи 'Стражей Галактики' Грут и Ракета предстают в необычном для себя антураже — на сцене оперы. Грут, воодушевленно держа микрофон, поет арию, в то время как Ракета, с листками текста в руках, выглядит немного растерянным. Зал театра наполнен зрителями, реагирующими смехом и удивлением на эту неожиданную встречу космоса и классического искусства. Сцена украшена роскошной декорацией, создавая атмосферу легкой комедии в духе анимационных фильмов Марвел. Это произведение создано с помощью нейросети midjourney, демонстрирующей детализацию и реализм в 3D-изображении. -
dalle Забавное Новогодье с Торами Парка Аттракционов. dalle
Yes_Ai прокомментировал remi изображение в галерее в Dalle примеры промтов
 Новый 2025 год в парке аттракционов обернулся необычным представлением с участием Тор и Халка. Супергерои добавили веселья и волнения в празднование, когда Тор пытался убедить Халка попробовать карусели, используя молот Мьёльнир и меч из сладостей. Вокруг героев Асгарда витал дух радости: дети в костюмах супергероев восхищались легендами, делая фотографии, а украшения создавали праздничную атмосферу. Этот магический вечер запомнился как начало нового года, полного улыбок и удивления, благодаря искусству нейросети DALLE-3.
Новый 2025 год в парке аттракционов обернулся необычным представлением с участием Тор и Халка. Супергерои добавили веселья и волнения в празднование, когда Тор пытался убедить Халка попробовать карусели, используя молот Мьёльнир и меч из сладостей. Вокруг героев Асгарда витал дух радости: дети в костюмах супергероев восхищались легендами, делая фотографии, а украшения создавали праздничную атмосферу. Этот магический вечер запомнился как начало нового года, полного улыбок и удивления, благодаря искусству нейросети DALLE-3. -
midjourney Фантазийный портрет куклы с элементами гранжа и точечного искусства. midjourney
Yes_Ai прокомментировал Ardi изображение в галерее в Midjourney примеры промтов
 Иллюстрация, созданная нейросетью midjourney, представляет собой фантазийный портрет куклы в стиле гранж и точечного искусства. Кукла обладает фарфоровой кожей и одета в разноцветную одежду из латок, украшенную вышивкой с космосом. В её глазах сочетается невинность и мудрость; они становятся центром портрета на сюрреалистическом фоне с танцующими звёздами и планетами. Работа выполнена в гиперреалистичном стиле, который затрагивает темы грани между фантастикой и реальностью, а также играет мотивами низкого искусства и высокого гротеска.
Иллюстрация, созданная нейросетью midjourney, представляет собой фантазийный портрет куклы в стиле гранж и точечного искусства. Кукла обладает фарфоровой кожей и одета в разноцветную одежду из латок, украшенную вышивкой с космосом. В её глазах сочетается невинность и мудрость; они становятся центром портрета на сюрреалистическом фоне с танцующими звёздами и планетами. Работа выполнена в гиперреалистичном стиле, который затрагивает темы грани между фантастикой и реальностью, а также играет мотивами низкого искусства и высокого гротеска. -
midjourney Сюрреалистический портрет небесного существа: вязаное чудо среди космо-арт пейзажа. midjourney
Yes_Ai прокомментировал Ardi изображение в галерее в Midjourney примеры промтов
 Сюрреалистический портрет небесного существа, выполненный в стиле космо-арт и текстильного искусства. Существо имеет тело из узоров вязания, переливающихся всеми цветами радуги, и украшено крыльями из лоскутков с эффектом северного сияния. Глаза существа содержат галактики, а его головной убор представляет собой звездную карту. Вокруг него разворачивается пейзаж с планетами в гранжевом стиле и звездами в духе поп-арта на фоне космического пространства с изображением туманностей. Произведение сочетает элементы гротеска и мультяшности, характерные для лоубро арта, и выполнено в высоком реализме, заставляя зрителя задуматься о границах между сюрреализмом и реальностью. Создание произведения осуществила нейросеть Midjourney через Telegram-бота.
Сюрреалистический портрет небесного существа, выполненный в стиле космо-арт и текстильного искусства. Существо имеет тело из узоров вязания, переливающихся всеми цветами радуги, и украшено крыльями из лоскутков с эффектом северного сияния. Глаза существа содержат галактики, а его головной убор представляет собой звездную карту. Вокруг него разворачивается пейзаж с планетами в гранжевом стиле и звездами в духе поп-арта на фоне космического пространства с изображением туманностей. Произведение сочетает элементы гротеска и мультяшности, характерные для лоубро арта, и выполнено в высоком реализме, заставляя зрителя задуматься о границах между сюрреализмом и реальностью. Создание произведения осуществила нейросеть Midjourney через Telegram-бота. -
midjourney Кукла в Патчеворк Платье и Сюрреализме Фотографии. midjourney
Yes_Ai прокомментировал Ardi изображение в галерее в Midjourney примеры промтов
 Игрушечная кукла в платье из лоскутков лавандового цвета с черными элементами, украшенная вышитым цветком подсолнуха и фарфоровым лицом с сюрреалистическими узорами. Она окружена витающими бабочками на фоне, стилизованном под гранж. Снимок выполнен в высокохудожественной манере с использованием техники точечной живописи, создавая зачаровывающий портрет в стиле лоубрайт. Работа создана ИИ midjourney и демонстрирует смешение классических техник искусства с современными элементами сюрреализма и гранжа.
Игрушечная кукла в платье из лоскутков лавандового цвета с черными элементами, украшенная вышитым цветком подсолнуха и фарфоровым лицом с сюрреалистическими узорами. Она окружена витающими бабочками на фоне, стилизованном под гранж. Снимок выполнен в высокохудожественной манере с использованием техники точечной живописи, создавая зачаровывающий портрет в стиле лоубрайт. Работа создана ИИ midjourney и демонстрирует смешение классических техник искусства с современными элементами сюрреализма и гранжа. -
midjourney Небесное Существо: Сюрреализм в Текстильной Вселенной. midjourney
Yes_Ai прокомментировал Ardi изображение в галерее в Midjourney примеры промтов
 Картина, сгенерированная нейросетью Midjourney, изображает фантастическое существо в стиле сюрреализма. Существо обладает бирюзовой прозрачной кожей и волосами цвета инопланетного изумруда. На голове у него головной убор, собранный из космических элементов — планет и туманностей. Оно парящее в пространстве тканого искусства, где вышитые звёзды соседствуют с узорами поп-арта на одежде необычного дизайна. Фон украшен взрывом цветов поп-арт стиля, смешивающим элементы высокого искусства и сюрреализма, отражая видения художников Йоджи Шимуры и Мобius. Произведение сочетает в себе гранж-реализм и лоубр аэстиктик, создавая уникальное переплетение стилей.
Картина, сгенерированная нейросетью Midjourney, изображает фантастическое существо в стиле сюрреализма. Существо обладает бирюзовой прозрачной кожей и волосами цвета инопланетного изумруда. На голове у него головной убор, собранный из космических элементов — планет и туманностей. Оно парящее в пространстве тканого искусства, где вышитые звёзды соседствуют с узорами поп-арта на одежде необычного дизайна. Фон украшен взрывом цветов поп-арт стиля, смешивающим элементы высокого искусства и сюрреализма, отражая видения художников Йоджи Шимуры и Мобius. Произведение сочетает в себе гранж-реализм и лоубр аэстиктик, создавая уникальное переплетение стилей.

