admin
-
Постов
499 -
Зарегистрирован
-
Посещение
-
Победитель дней
9
Весь контент admin
-
 а каков правильный ответ ?
а каков правильный ответ ? -
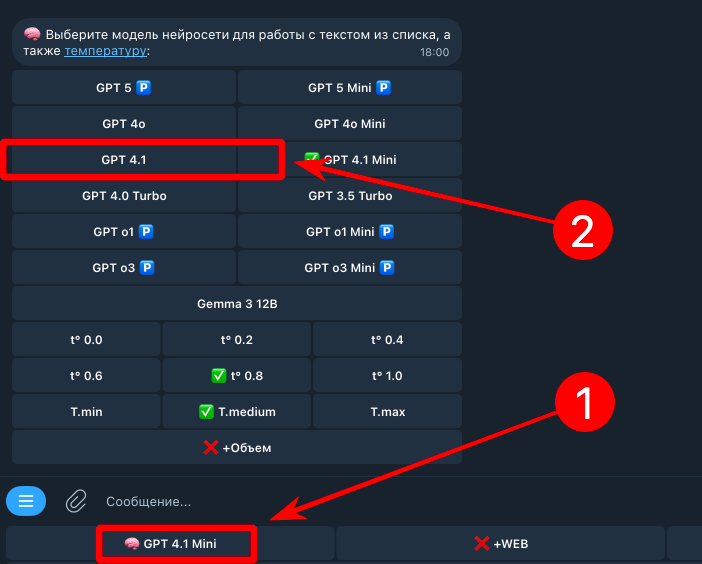
Вот тут доступна эта нейросеть: https://t.me/yes_ai_bot?start=_chatgpt Когда перейдете по этой ссылке, нажмите на выбор нейросети в нижнем меню, а затем выберите GPT 4.1, как показано на скриншоте

-
Chat GPT 4.1 пробовали ?
-
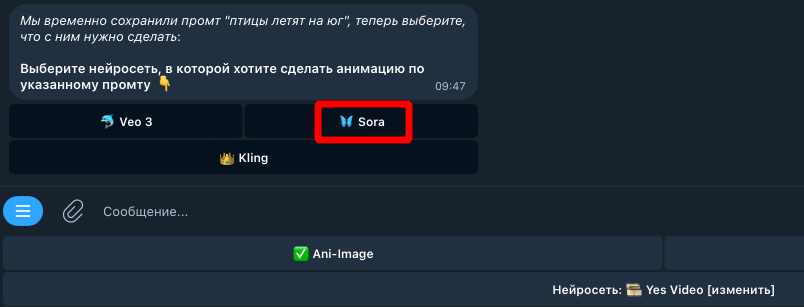
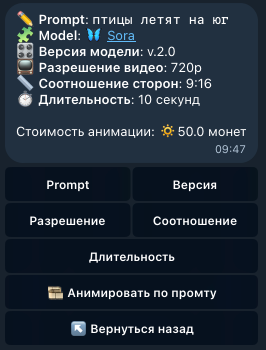
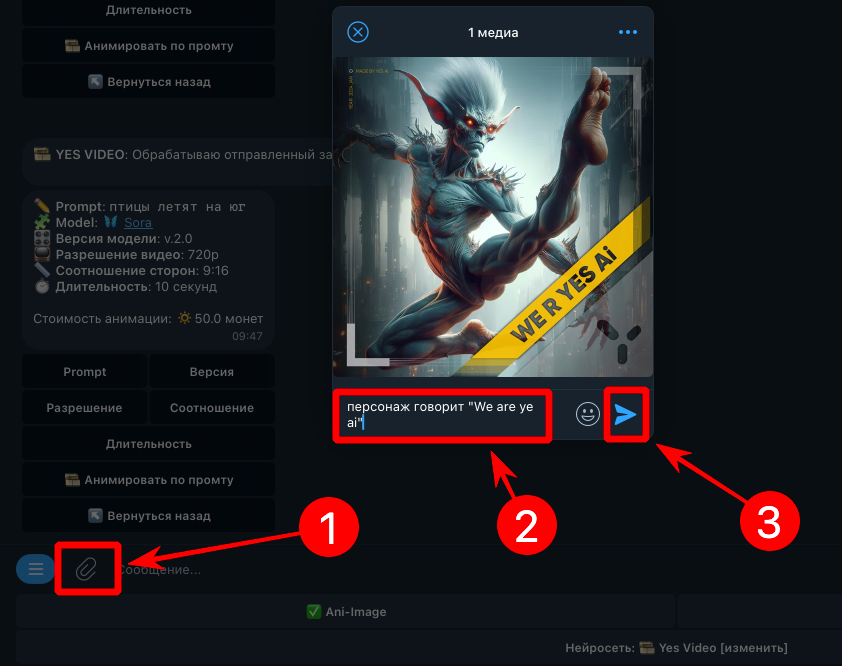
Sora 2 — это нейросеть OpenAI для генерации видео, с помощью которой можно создавать ролики по текстовому описанию и стартовому кадру. Официальный запуск Sora 2 состоялся в октябре 2025 года. Ключевые возможности Sora 2: генерация видео со звуком и диалогами, высокое качество видео до 1080p, поддержка разных языков в промтах и озвучке. Если вы хотите понять, как пользоваться Sora 2 для создания реалистичных видео кинематографического качества, начните с базовых возможностей и ограничений нейросети. С помощью Sora 2 можно создавать целые клипы, генерируя их отрезками по 10 или 15 секунд. В Sora 2 уже поддерживается стартовый кадр, что позволяет продлевать ролики по аналогии с Veo 3 [см. описание]. Нейросеть Sora 2 доступна в двух версиях, и перед началом работы важно выбрать подходящий вариант для генерации видео: Базовая версия Sora 2 поддерживает генерацию видео в разрешении 720p длительностью 10 или 15 секунд. Обычно такие ролики создаются за несколько минут. Расширенная версия Sora 2 Pro позволяет генерировать видео в 720p или 1080p, поддерживает длительность 10 или 15 секунд и лучше прорабатывает детали. Время генерации обычно составляет от 5 до 10 минут и более. Преимущества Sora 2 для генерации видео Реалистичность (почти неотличимая от реальности физика взаимодействия персонажей с предметами и друг с другом); Высокое качество видео (от 720p до 1080p); Альбомный и портретный форматы (16:9 и 9:16); Длительность (10 и 15 секунд на выбор); Поддержка референсов (картинка в качестве стартового кадра); Озвучка диалогов на разных языках, в том числе на русском; Автоматическая генерация окружающих звуков и эффектов; Нативная поддержка текста промтов на большинстве языков (не требуется перевод на английский); Понимание промтов на очень высоком уровне (нейросеть выполняет почти всё, что описано в тексте). Примеры генераций из Sora 2 можно посмотреть в нашей группе в Телеграм: https://t.me/yes_ai_chat/130591 Ограничения и недостатки нейросети Sora 2 Наличие водяного знака на видео (если у нейросети есть на это основания, см. описание ниже); Запрещено использовать в качестве референсов реалистичные изображения и фотографии (допускаются только арты, аниме, рисунки или фотографии без присутствия людей). Исключение — функция "Камео", когда в качестве референса используется образ реального человека (поддерживается только в официальном мобильном приложении); Запрещено использовать в качестве референсов изображения, на которых присутствуют любые известные персонажи фильмов, мультфильмов и пр.; Запрещено в промтах указывать имена любых известных персонажей, защищенных авторскими правами; Видео с высоким разрешением генерируются достаточно долго (10+ минут), но это нельзя считать полноценным недостатком; Иногда реплики или музыкальное сопровождение обрываются в неудачный момент (не полностью умещаются в отведенный временной интервал); Sora 2, как и прочие нейросети от OpenAI, недоступна на территории РФ и некоторых других стран. Однако этот недостаток можно обойти, используя Yes Ai Bot в мессенджере Telegram; Если сравнивать с Veo 3, то Sora 2 обойдётся дороже, ведь для полноценного доступа ко всем функциям придётся платить по $200 в месяц (без учёта VPN и других побочных расходов). Но в Yes Ai генерации можно делать без оплаты месячных тарифов. ⚠️ Внимание! В нейросети Sora 2 запрещено генерировать контент категории NSFW (not safe for work) и диалоги с нецензурной лексикой — за подобные попытки можно получить бан. Как генерировать видео в Sora 2 без водяного знака Нейросеть добавляет водяной знак, чтобы снизить риск создания фейков и сомнительных материалов, однако в некоторых случаях можно сгенерировать видео в Sora 2 без вотермарка. Как работает водяной знак в Sora 2: Если вы генерируете видео в Sora 2 с использованием стартового кадра (референса), водяной знак будет всегда. Если вы генерируете видео только по промту, но в нём есть прямые или косвенные указания на фотореалистичность, водяной знак будет присутствовать. Если видео создаётся по промту, в котором упоминаются конкретные личности, водяной знак будет присутствовать. Если промт выглядит нейтральным с точки зрения нейросети, водяного знака, как правило, не будет. Как сгенерировать видео в Sora 2 по промту без референса через Yes Ai Bot Откройте Sora 2 в Telegram по ссылке: https://t.me/yes_ai_bot?start=_soravideo2 Отправьте промт для генерации видео на любом языке. В появившемся меню выберите нейросеть "🦋 Sora". Нажмите кнопку "Версия" и выберите "Sora 2" или "Sora 2 Pro". Установите расширенные настройки, доступность которых зависит от выбранной версии: соотношение сторон, разрешение и длительность видео. Запустите генерацию. Как сгенерировать видео в Sora 2 по промту со стартовым кадром через Yes Ai Bot Откройте нейросеть Sora 2 в Telegram по этой ссылке https://t.me/yes_ai_bot?start=_soravideo2 Прикрепите к сообщению 📎 стартовый кадр (изображение) и одновременно отправьте описание сцены — промт. В появившемся меню выберите нейросеть "🦋 Sora". Нажмите кнопку "Версия" и выберите "Sora 2" или "Sora 2 Pro". Установите расширенные настройки, доступность которых зависит от выбранной версии: соотношение сторон (формат), разрешение, длительность. Запустите генерацию. Количество видео, которые можно одновременно генерировать в Yes Ai через Sora 2, зависит от вашего тарифа. На бесплатном тарифе видео можно создавать только по одному, последовательно. Описание всех тарифов [смотрите здесь]. Обновление от 15 октября: мы опубликовали инструкцию по написанию промтов для Sora 2, и её стоит прочитать перед началом работы с нейросетью. https://forum.yesai.su/topic/3297-sora-2-kak-pisat-pravilnye-prompty-dlya-sozdaniya-video-s-pomoschyu-neyroseti/ Референсы, то есть стартовые кадры для Sora 2, можно создавать в других нейросетях. Для создания стартовых кадров для Sora 2 лучше всего подойдут: Sora Images (оптимальный вариант) Midjourney Если у вас возникнут вопросы по работе с Sora 2 или другими нейросетями, обратитесь в чат нашего [телеграм-сообщества].
- 3 ответа
-
- 2
-

-
- sora 2
- sora video
- (и ещё 2 )
-
Эта команда допустима к использованию только через оригинальный миджорни. Во всех сторонних сервисах эти команды обрезаются в целях безопасности.
-
Для этого вам не нужен тарифный план, достаточно покупать монеты для генераций. Вы тратите монеты по мере необходимости.
-
Нейрофотосессия — это создание фотографий в нейросети по вашей фотографии: вы загружаете снимок, а система автоматически подбирает стили, локации и генерирует новые изображения. С помощью Qwen Images можно сделать нейрофотосессию онлайн и получить разные образы без участия фотографа. В этой статье разберём, как сделать нейрофотосессию в Qwen Images и сгенерировать фото по своей фотографии. Ранее мы уже рассказывали, как Qwen Images обрабатывает изображения, в том числе фотографии, и помогает создавать новые фото в нейросети. Если вы пропустили этот материал, вот ссылка на подробный разбор возможностей Qwen Images [вот ссылка]. Как работает нейрофотосессия в Qwen Images Разберём, как сделать нейрофотосессию в Telegram на примере бота @yes_ai_bot: в нём доступны функции Qwen Images, включая генерацию и стилизацию фото. В Qwen Images доступны два основных варианта нейрофотосессии: по вашей фотографии; по текстовому описанию и вашей фотографии. Первый способ — загрузить в бот фотографию, на которой хорошо видно лицо, и выбрать количество изображений на выходе: 5 или 10. Каждое изображение будет сгенерировано в уникальном стиле и в новой локации. 🚩 Этот метод иногда создаёт изображения с неточностями: например, нейросеть может не на всех фото правильно определить пол человека или цвет волос. Поэтому рекомендуем указывать важные детали в текстовом описании к фото — см. второй способ ниже 👇 Вот несколько примеров: Второй способ — загрузить фотографию и добавить текстовое описание, или промт, который нейросеть должна учесть при генерации фото. 👆 В нашем примере нейросеть добавила девушке в кадр стакан апельсинового сока. Одно из самых полезных применений этой функции — управление положением человека в кадре: например, можно отправить фото, на котором человек виден не полностью, и указать в промте «в полный рост». В результате нейросеть может сгенерировать изображение человека в полный рост, как будто камера находится дальше. Примеры промтов для управления нейрофотосессиями: в полный рост / сидит в кресле / смотрит вверх и т. д.; только лицо; держит в руках... (укажите, какие предметы человек должен держать в руках); голубые глаза / фиолетовые светящиеся глаза (если нужно изменить цвет глаз); зелёные волосы / длинные волосы / лысый и др.; в средневековом платье / в джинсах (можно переодевать персонажа); с улыбкой / плачет / смеётся (управление эмоциями). Иными словами, в промте можно описать почти любые пожелания, но нейросеть не всегда точно интерпретирует запрос. Рекомендуем сначала запускать нейрофотосессию на минимальном количестве изображений — 5 штук. Если часть изображений получилась неудачно, попробуйте повторить генерацию с другой исходной фотографией. Если на фотографии несколько человек, лучше сразу указать в промте, что нужно стилизовать всех, иначе нейросеть может обработать только одного человека. 🚩 Чтобы нейросеть точнее сгенерировала изображение, укажите в промте пол человека. Как сделать нейрофотосессию через Telegram-бота Yes Ai Краткая инструкция: Перейдите в Telegram-бота по ссылке: @yes_ai_bot Отправьте 📎 фотографию человека, для которого хотите сделать нейрофотосессию. Важно: если нужно, чтобы нейросеть обработала фотографию определённым образом, добавьте к ней текстовое описание — промт, на любом языке. В появившемся меню нажмите кнопку «👩🎨 Нейрофотосессия». Выберите, сколько фотографий хотите получить в результате. Дождитесь результатов: время обработки зависит от количества выбранных генераций. От чего зависят размер и пропорции изображений в нейрофотосессии? Всё просто: нейросеть сохраняет пропорции и размер исходной фотографии. Отправили «квадрат» — получите «квадрат» на выходе и т. д. После генерации нейрофотосессии каждая фотография придёт отдельным сообщением в боте, а затем любое изображение можно будет дополнительно стилизовать или изменить с помощью расширенных функций. При запуске нейрофотосессии система подбирает случайные стили и локации, поэтому один и тот же снимок можно генерировать несколько раз и получать разные результаты. Если вам понравилось изображение, его можно увеличить без потери качества с помощью [функции Upscale] Если у вас возникнут вопросы по работе с Qwen Images или другими нейросетями, обращайтесь в наш Telegram-чат.
- 1 ответ
-
- 3
-

-
-
- нейрофотосессия
- qwen
- (и ещё 2 )
-
Все верно, для получения бесплатных генераций нужно кому-то порекомендовать бота, так как бесплатные генерации не являются неотъемлемой частью тарифа, это по сути бонус от администрации. Буквально двумя сообщениями выше был подробно разобран и этот вопрос. Рекомендуем прочесть: https://forum.yesai.su/topic/621-bezlimitnyy-dostup-k-neyrosetyam-v-yes-ai-bot/?do=findComment&comment=5159
-
Здравствуйте, согласно прайсу (по ссылке): https://yesai.su/prices 1 генерация Sora Images: 🔅0.7 монет Каждая генерация в Sora Images - это 4 картинки по 🔅0.7 монет В день баланс на пакетах VIP восстанавливается на 🔅100 монет, делаем несложный расчет: ( 100 / 0.7 ) * 30 = 4260 изображений в месяц ИЛИ 142 в сутки. Но в пакетах VIP можно брать монеты авансом со следующего дня, что позволит делать больше генераций ежедневно. Подробнее про авансы написано тут: https://t.me/yes_ai_official/1359 Кроме того, монеты можно покупать отдельно (без покупки пакета VIP), в этом случае стоимость будет тем ниже, чем большее количество монет покупаете за раз. Для покупки монет или тарифов отправьте боту @yes_ai_bot команду /tariffs
-
Рекомендуем для создания обложек использовать нейросеть Sora Images, вот ссылка: https://t.me/yes_ai_bot?start=_soraimages Пример промта: обложка книги с зеленой обложкой, название книги "Живая энергия Жизни". красивые золотые узоры. Автор "LUBAVA" Вы можете добавлять к промту любые пожелания в свободной форме, вот еще пример для управления цветом обложки: обложка книги с зеленой обложкой разных оттенков, название книги "Живая энергия Жизни". красивые золотые узоры. Автор "LUBAVA"
-
Отвечаем по порядку важности тезисов, касающихся бесплатных генераций в нейросетях для пакетов VIP. Пункт номер НОЛЬ: Уважаемый Makentosh, объясняем, почему у вас не сработали бесплатные генерации. К сожалению, вы в данном обращении НЕ указали, что использовали именно нейросеть Flux.1. Однако именно для нее в условиях предоставления бесплатных генераций указано следующее: «Генерации изображений в нейросети Flux.1 (при максимальной ширине и/или высоте не более 1024 пикселей), в том числе с использованием моделей LoRA». Чего вы не учли: при генерациях у вас использовалось соотношение сторон 900×1600 пикселей — это выходит за рамки действия безлимита для нейросети Flux.1. Как решить эту проблему в будущем? Пожалуйста, читайте описание внимательнее 🙏 Но для полноценного ответа на вопрос о бесплатных генерациях мы упомянем и другие важные пункты, с которыми часто сталкиваются пользователи. 1. Важно понимать, что бесплатные генерации (с разумными ограничениями) не являются неотъемлемой частью пакетов VIP. Данная опция предоставляется по усмотрению администрации для обладателей пакетов VIP. Об этом написано в оферте в начале этого топика: «Данное предложение не является офертой, Yes Ai оставляет за собой право изменить правила предоставления безлимитов в любой момент». Если вы поняли, что это НЕ является офертой, двигаемся дальше. 2. Если пользователь очень активно пользуется ботом, у системы есть основания полагать, что он потенциально может злоупотреблять безлимитными генерациями, либо использует телеграм-аккаунт не один, либо автоматизирует действия внутри системы. По этой причине (для обеспечения безопасности) бесплатные генерации временно ограничиваются для пользователя. Важно: система ничего не утверждает, в частности — НЕ утверждается, что пользователь совершает какие-либо действия со злым умыслом, НО система вправе ограничить бесплатные генерации для обеспечения собственной безопасности. 3. Ограничения на бесплатные генерации в пакетах VIP накладываются автоматически, точно так же (автоматически) они снимаются спустя некоторое время. Когда снимается ограничение на бесплатные генерации: рекомендуем подождать до СЛЕДУЮЩЕГО дня, либо для генераций вы можете использовать монеты, которые включены в пакет. Напоминаем, что вы можете забирать монеты авансом из пакета — об этом рассказано здесь: https://t.me/yes_ai_official/1359 4. Как избежать ограничений бесплатных генераций на пакете VIP в будущем? Всего два простых тезиса: Если пользователь ведет среднестатистический образ жизни (спит, делает перерывы на обед, иногда отдыхает от нейросетей) и не использует бота постоянно, то бесплатные генерации не отключатся вплоть до окончания срока действия пакета VIP. Если пользователь генерирует в нейросетях больше, чем среднестатистический человек, для него действуют стандартные опции пакета VIP, описанные в тарифах: https://forum.yesai.su/topic/412-tarify-yes-ai-bot (в том числе ежедневные начисления монет, баллов и возможность получать монеты и баллы авансом).
-
нейросеть Sora Images не поддерживает негативные промты в чистом виде, вместо этого следует четко указывать, что именно вы хотите видеть на изображении. Например, если вы не хотите, чтобы на человеке был синий пиджак, то просто укажите, какого цвета должен быть этот пиджак. Другими словами, нужно просто более подробно описывать то, что вы хотите видеть.
-
Следует задавать вопросы более конкретно, о какой нейросети идет речь ? Но, если коротко, все цены указаны в прайсе: https://yesai.su/prices
-
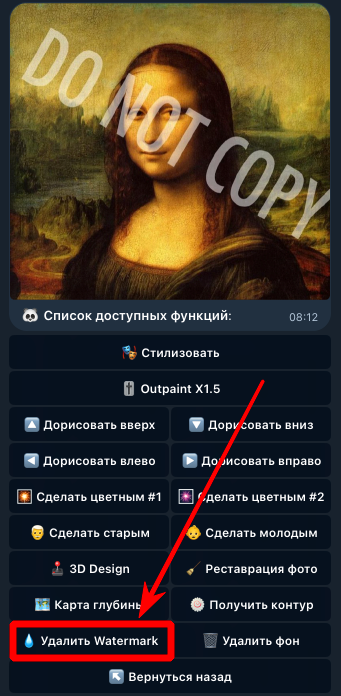
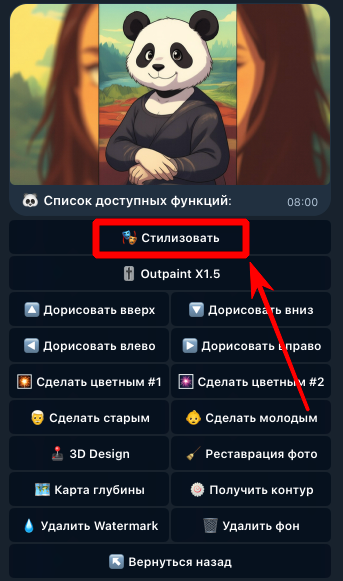
Нейросеть Qwen Images подходит не только для генерации, но и для обработки изображений и фото: стилизации, удаления фона, реставрации фотографий и редактирования картинок по промту. Список возможностей Qwen Images уже очень широк и будет расширяться с выходом обновленных моделей Qwen Image Edit. Вот основные функции Qwen Images для обработки фото и изображений: изменение отдельных деталей на изображении по описанию в промте; стилизация фото и картинок (например, применение аниме-стиля к фотографии) [выполнить в боте] удаление водяных знаков с изображения [выполнить в боте] реставрация старых фотографий и улучшение качества фото [выполнить в боте] генерация фотографий интерьера по чертежам или наброскам; генерация чертежей (контуров) интерьера по фотографиям; раскрашивание черно-белых фотографий [выполнить в боте] удаление фона с изображения или замена фона на белый [выполнить в боте] [beta] Outpaint — дорисовка областей изображения с учетом контекста (справа, слева, сверху, снизу или вокруг); преобразование объектов и персонажей в их 3D версии; поворот объектов и персонажей; генерация карты глубины по картинке; изменение возраста персонажей (сделать старше или моложе); замена одежды на человеке по описанию; [скоро] замена одежды на человеке по фотографии; замена черт лица, цвета кожи и прочих деталей у людей и персонажей; исправление дефектов внешности; [unstable] экстракция (извлечение) элементов одежды с фотографий. В этом списке перечислены далеко не все возможности обработки изображений в Qwen. Важно отметить, что у нейросети нет жестко заданных встроенных режимов для каждой задачи: вы отправляете в Qwen картинку и промт с описанием того, что нужно сделать, а ИИ редактирует изображение, опираясь на текст запроса. 👆 Этот момент является ключевым! С одной стороны, возможность самостоятельно описывать нужные изменения позволяет гибко редактировать изображения, но у такого подхода есть несколько недостатков: результат преобразования может сильно зависеть от исходного изображения. Например, функция Outpaint (дорисовка), доступная в Yes Ai Bot, на одних картинках дает стабильный результат, а на других может добавлять пустые области без учета контекста. Сейчас эта функция работает в бета-режиме; нейросеть может не сразу понять задачу, поэтому для стабильного результата иногда приходится подбирать более точный промт; некоторые задачи нейросеть может выполнять нестабильно, и это становится понятно только после теста. 💡 Обязательно учитывайте описанные выше особенности: оплата берется за сам факт генерации, а не за конечный результат. Подробнее об этом рассказано в статье "Почему нейросети не возвращают деньги". Хорошая новость в том, что Qwen — достаточно продвинутая нейросеть для обработки изображений, которая справляется с перечисленными задачами лучше многих конкурентов. Да, иногда нужный результат получается не с первой попытки, и во многих случаях достаточно доработать промт — это приходит с опытом. В Telegram-боте Yes Ai многие функции Qwen для обработки изображений доступны в «однокнопочном» формате: достаточно отправить боту картинку и выбрать нужную кнопку из списка. Это заметно упрощает редактирование фото. Разберем на примерах. Как удалить водяной знак с изображения в Qwen откройте бота по ссылке @yes_ai_bot отправьте изображение, с которого нужно удалить водяной знак; в появившемся меню откройте список доступных функций кнопкой "🐼 Функции Qwen"; нажмите на кнопку "💧 Удалить Watermark" и дождитесь результата. Как стилизовать фото в Qwen Стилизация фото в Qwen позволяет полностью изменить визуальный стиль изображения, сохранив при этом общие черты персонажей, лица и окружения. Покажем это на примере: переходим в бота по этой ссылке @yes_ai_bot отправляем фотографию, например, с вашим прекрасным лицом; в появившемся меню нажмите кнопку "🎭 Стилизовать"; выберите любой из стилей в списке (обратите внимание, что список можно листать влево и вправо), стилизация запустится автоматически, останется только дождаться результата. Как редактировать изображения по промту в Qwen Выше мы разобрали функции Qwen, которые разработчики Yes Ai вынесли в отдельные кнопки, но основной возможностью остается редактирование изображений по собственным промтам. В этом случае вам нужно самостоятельно описать текстом, как именно следует изменить исходное изображение. Писать промты для Qwen Images можно на любом языке и в свободной форме, если вы работаете через Yes Ai Bot. Однако старайтесь не перегружать задачу лишними деталями: лаконичный и точный промт обычно работает лучше. Откройте бота Yes Ai. Отправьте изображение вместе с текстовым примечанием, оно будет автоматически применено в качестве промта при генерации. В появившемся меню нажмите кнопку "🌇 Референс картинки" и дождитесь результата. Все инструменты редактирования изображений в боте Yes Ai работают по следующим принципам: Пропорции при генерации берутся из исходного изображения, а не из базовых настроек бота. Если используются функции категории «Outpaint», пропорции вычисляются автоматически, но площадь изображения, сгенерированного нейросетью, ограничена порогом в 1,2 мегапикселя. Если результат нужно увеличить, используйте отдельный инструмент: [Как сделать апскейл картинки через нейросеть] Если вы хотите сделать Outpaint, не указывайте это в промте при использовании функции "🌇 Референс картинки". Дорисовка работает только через отдельные функции в меню "🐼 Функции Qwen". В ближайшее время мы расширим эту инструкцию, так как уже работаем над новыми возможностями обработки изображений в Qwen Image Edit. Об обновлениях мы сообщим в нашем Telegram-канале: https://t.me/yes_ai_official По всем вопросам обращайтесь в наш чат: https://t.me/yes_ai_talk Если вы еще не читали первую статью с описанием базовых функций Qwen, то следует сделать это:
-
- 4
-
-
-
- обработка изображений
- удаление фона
- (и ещё 3 )
-
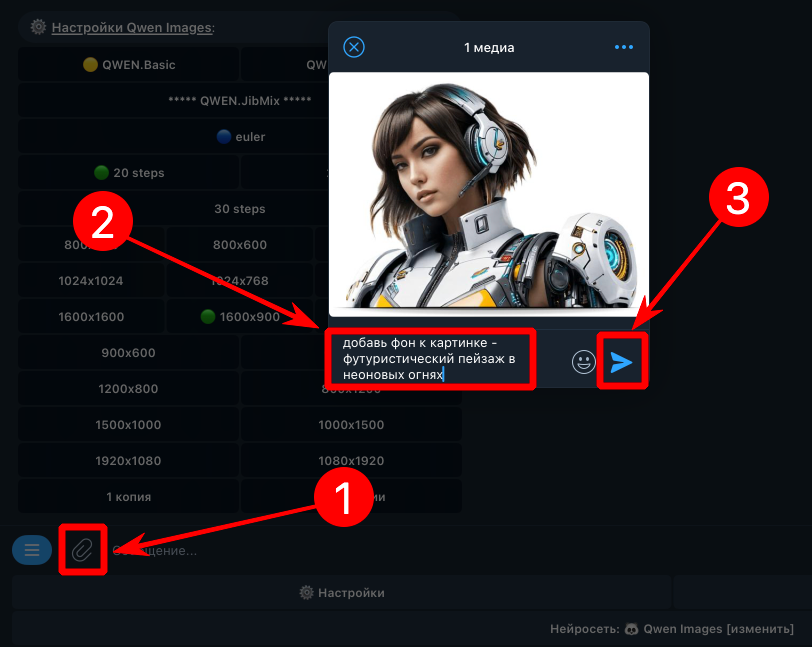
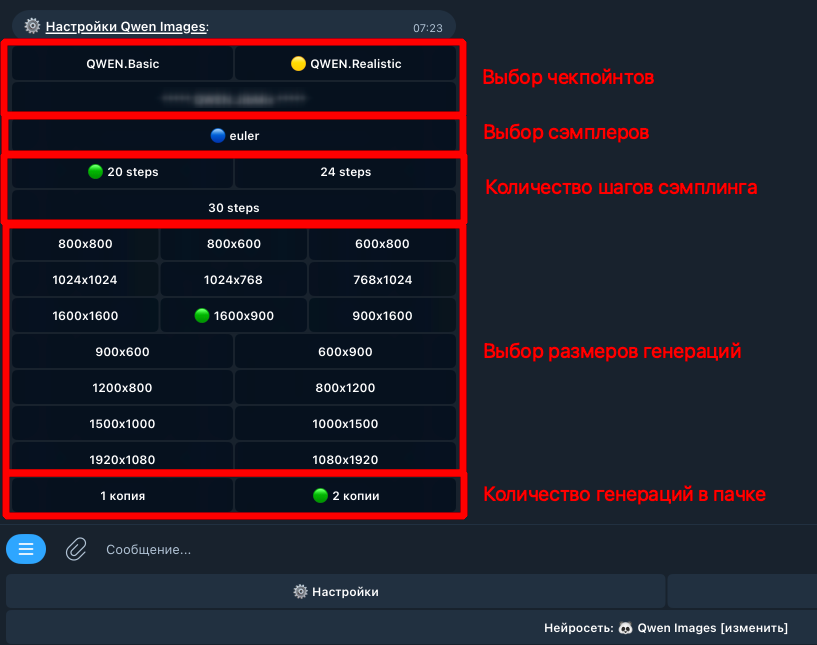
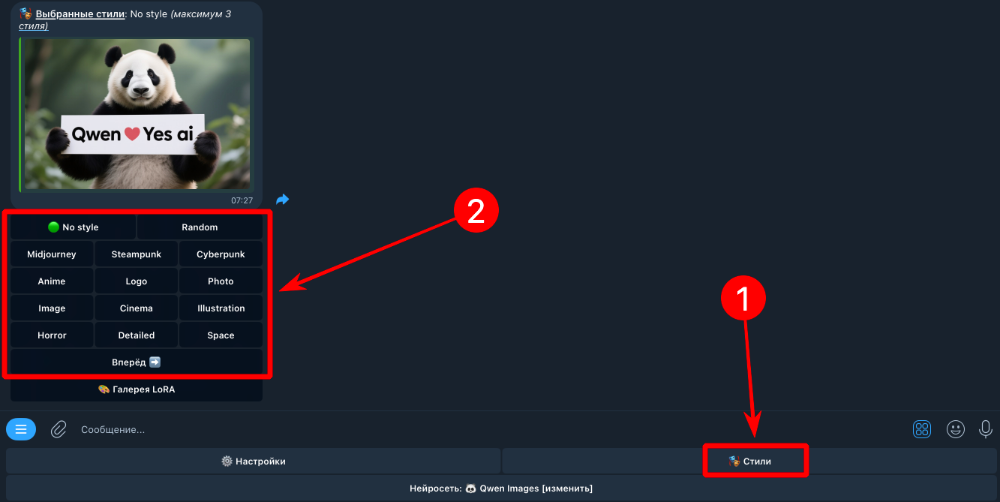
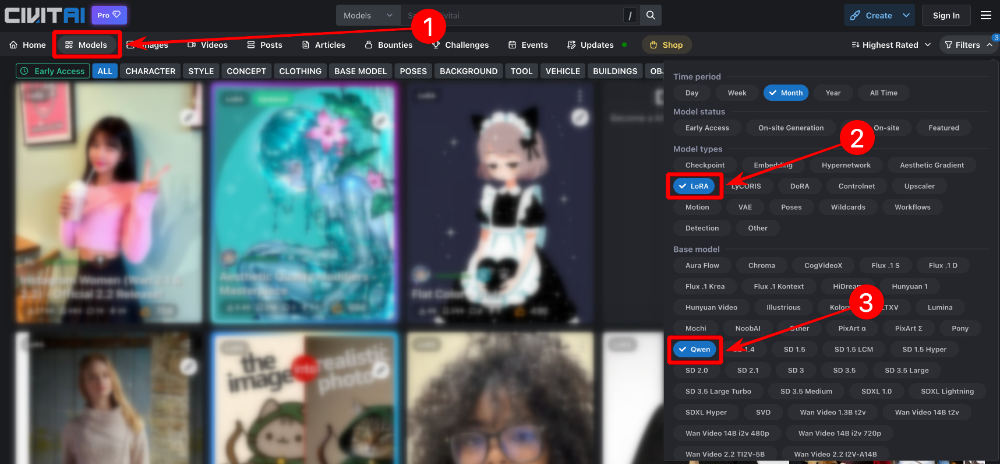
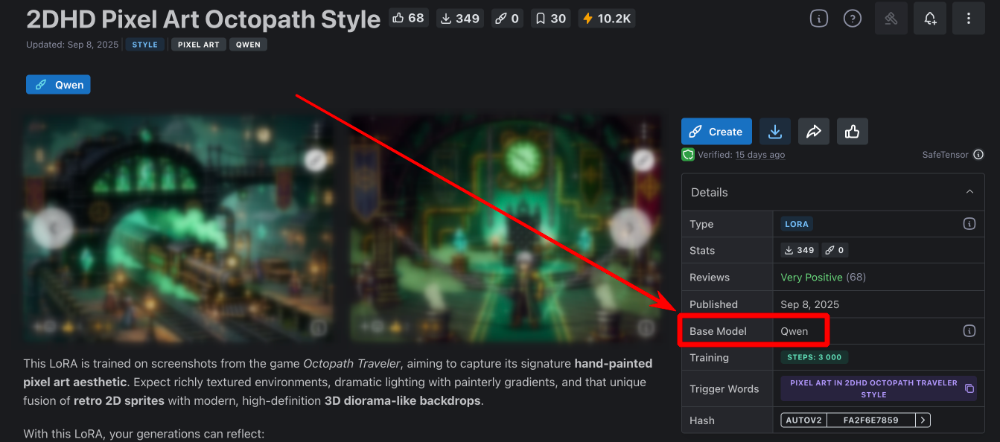
Нейросеть Qwen Images от разработчиков из Китая, хоть и можно условно назвать логическим продолжением Flux.1, ведь уровень качества их генераций очень близок, но в некоторых аспектах Qwen на голову выше оппонента. Нейросеть Qwen справляется с множеством задач, но основной "фишкой" можно без сомнений считать широкие возможности обработки изображений, а не простые генерации по промтам. Объясним суть проблем, которые способна решить нейросеть Qwen. Обработка изображений Проблема большинства пропиетарных нейросетей (Midjourney, Sora Images и пр.), предоставляющих возможность обрабатывать ваши изображения, заключается в том, что в них используются через чур жесткие NSFW-фильтры (not safe for work), которые часто ограничивают генерации, которые НЕ содержат ничего запрещенного. А Квен может быть установлен на собственных серверах, поэтому фильтрация контента будет работать более адекватно. Да, базовые версии Qwen не генерируют NSFW, так как не обучены для этих целей, но за мелкие нарушения вы хотя бы не получите бан. Если будет замечено подозрение на "запрещенку", то генерация будет выполнена в "дистиллированном" виде (без NSFW). А теперь перейдем к самой важной части — к функциям обработки картинок. Вы можете загрузить в Qwen собственные изображения с целью переработки и стилизации, вот некоторые опции: Замена одежды на персонаже или иные модификации окружения с сохранением черт лица оригинала (нейросети Midjourney и Sora Images молча завидуют Квену =) ) [скоро] Объединение нескольких изображений (аналогично тому, как это работает в Sora Images). [скоро] Замена одежды на человеке по фотографии человека и элементов одежды. [скоро] Поддержка карты глубины (depth map) (из Control.Net) для получения более предсказуемых результатов. [скоро] Поддержка шаблонов Open Pose для управления позами персонажей (из Control.Net). Замена стиля на тот, который описан в промте, например, из собственной фотографии можно создать аниме аватар [выполнить в боте] Реставрация старых фото в один клик [выполнить в боте] [beta] Дорисовка областей слева, справа, внизу, вверху, вокруг (Outpaint), пока работает не для всех картинок, но это решаемо. Расскажем об этом в отдельной статье. Колоризация черно-белых фото (сделать фотографии цветными) [выполнить в боте] Реставрация фото без изменения образов персонажей. Преобразование объектов в 3D-модели. [beta] Экстракция одежды для маркетплейсов (работает не очень стабильно). Можно с фотографии вытащить одежду. Удаление водяных знаков [выполнить в боте] Удаление фона (замена фона на белый) [выполнить в боте] Свободная модификация картинок с использованием произвольного промта. ...это далеко не все. Полный список возможностей почти безграничен, ведь вы сами можете описать, что именно нужно сделать с фотографиями. Неплохой список достоинств, не правда ли ? Это не все, вот еще пара важных моментов... Лица людей при модификации референсов не изменяются (остаются оригинальными), если иное не указано в промте. Умеет писать текст на английском и китайском, причем, не просто текст, а слова и фразы, разделенные на фрагменты. Например, можно сделать обложку журнала, где будет четко выделен заголовок, название и дополнительные блоки текста. Квен поддерживает LoRA (Low-Rank Adaptation), вы можете расширять базу знаний Qwen за счет обученных моделей, которые можно установить, например, с сайта civitai.com в Yes Ai Bot (в мессенджере Телеграм). Недостатки нейросети Qwen Images Qwen — не волшебная палочка, а нейросеть, способности которой не безграничны. Перечислим некоторые сложности, с которыми вы можете столкнуться: При дорисовке (Outpaint) добавляемые области могут не всегда соответствовать референсу, но эта проблема часто решается повторными попытками или пост-модификациями Достаточно высокая нагрузка на железо, без дорогостоящего оборудования практически не обойтись (либо придется долго ждать генераций). Рекомендуем видеокарты не ниже NVIDIA 3090, в идеале 4090 или 5090, так что придется выложить из кармана лишние (или не лишние?) несколько тысяч долларов. Жалко денег? Тогда не придется покупать собственное железо, все функции Qwen доступны в Telegram-боте @yes_ai_bot При работе с референсами иногда может происходить неожиданная замена элементов, например, фона, хотя в промте об этом не упоминалось Не самая богатая база знаний терминов, словарный запас заметно ниже, чем у той же Sora Images Не поддерживаются никакие языки кроме английского и китайского Как сгенерировать картинки в Qwen Images Разберем процесс на примере Yes Ai Bot, в котором доступна эта нейросеть. Перейдите по ссылке в Телеграм-бота @yes_ai_bot Сделайте настройки, если необходимо: можно выбрать модель (чекпойнт), количество шагов сэмплинга (почти всегда достаточно 20), размер генераций (в пикселях) и количество генераций для каждого запроса. Выберите стиль из галереи, если лень самостоятельно придумывать сложные промты. Отправьте промт на любом языке (сервис Yes Ai автоматически переведет его на английский). Настройки для нейросети Qwen Images: модель (чекпойнт): определяет базовую стилистику изображения, чекпойнты обучены на разных дата-сетах, что позволяет им делать совершенно уникальные генерации. Например, можно выбрать чекпойнт, который больше "заточен" под генерации в стиле реализм, если требуется повышенная фотореалистичность; количество шагов сэмплинга: чем их больше, тем большее количество раз нейросеть будет "додумывать" содержимое генераций, но тем больше будет стоимость и время ожидания. В 99% случаев будет достаточно 20 шагов; размер генераций: вы можете выбрать формат 1:1 / 2:3 / 3:2 / 9:16 / 16:9, причем доступны различные размеры (в настройках они указаны в пикселях); количество генераций: если выбрана 1 копия, то на каждый отправленный промт будет создаваться только 1 картинка, если выбрано 2 копии, то будет два уникальных результата и т.д. Если вам нужны примеры промтов для генераций, рекомендуем открыть бесплатную галерею на нашем форуме. Как генерировать изображение в Qwen Images с использованием моделей LoRA Если коротко, то нужно делать все то же самое, что описано предыдущей 👆 инструкции, но к тексту промтов требуется добавлять ключ с номером заранее установленной модели LoRA и весовым коэффициентом. Пример промта с использованием Qwen LoRA: панда кушает лапшу из миски <lora:1938784:1.1> pixel art in 2dhd octopath traveler style ...где <lora:1938784:1.1> — это ключ активации модели LoRA: "1938784" - номер модели с сайта civitai.com "1.1" - это весовой коэффициент, обычно он варьируется в диапазоне от 0.7 до 1.5 (зависит от того, как была обучена выбранная модель Лоры) "pixel art in 2dhd octopath traveler style" - триггерные слова для активации модели А теперь разберемся, где брать номер LoRA для ключей формата <lora:1938784:1> Во-первых в Yes Ai Bot есть галерея моделей Лора, которые ранее были установлены другими пользователями. Вы можете копировать ключи моделей прямо оттуда, но не забывайте вставлять в промт и триггерные слова, если они присутствуют в карточке описания. Как установить модель Qwen LoRA с сайта Civitai в галерею Yes Ai Если вам не хватает выбора моделей из галереи Yes Ai, добавьте то, что найдете на сайте Civitai (это большая библиотека моделей, обученных энтузиастами со всего мира). Для начала вам нужно определиться, какую модель планируете использовать для генераций, сделать это можно на сайте Civitai по ссылке: https://civitai.com/models. ⚠️ В фильтрах выберите два пункта: "LoRA" и "Qwen". В появившемся списке выберите понравившуюся модель, отвечающую вашей идее по стилистике или функциям (читайте описания моделей, в них авторы пишут, что именно делает та или иная Лора). Перейдите в карточку модели и скопируйте ссылку из строки браузера, например: https://civitai.com/models/1938784/2dhd-pixel-art-octopath-style Скопированную ссылку нужно отправить боту Yes Ai в Телеграм, система все проверит и добавит модель в галерею в течение 5-15 минут. Обратите внимание, что для Qwen можно устанавливать только те модели, у которых стоит пометка "Base model: Qwen". А когда будете отправлять ссылку боту, убедитесь, что в нижнем меню выбрана именно нейросеть Qwen: надпись на кнопке "Нейросеть: Qwen Images [изменить]". Когда Лора будет успешно добавлена в систему, вы можете отправлять промты, содержащие соответствующий ключ, в нашем примере он будет выглядеть так: <lora:1938784:1>, где 1938784 — это номер модели (его можно увидеть в ссылке, которую вы скопировали с сайта Civitai. Тут явно чего-то не хватает! Не хватает триггерных слов, ведь они были предусмотрены автором этой модели (речь про "671809"). Триггерные слова — это текст, который требуется отправлять вместе с вашим промтом, чтобы LoRA работала именно так, как задумал автор. Для рассматриваемой модели действительно предусмотрена триггерная фраза: pixel art in 2dhd octopath traveler style Теперь собираем все по частям, нам нужен промт, который создаст картинку с пандой... панда кушает лапшу из миски <lora:1938784:1> pixel art in 2dhd octopath traveler style Может возникнуть логичный вопрос "А ничего, что часть промта написана на русском языке, а триггерные слова на английском?". Отвечаем: Не беспокойтесь об этом, система Yes Ai автоматически все отрегулирует и сделает правильную генерацию, так что можно миксовать два языка в одном запросе. Если вы используете Qwen на своем компьютере, то необходимо весь промт вводить на английском языке. Как выбирать весовой коэффициент для Лоры и на что он влияет? Весовой коэффициент для LoRA определяет силу ее воздействия на создаваемую генерацию, чем он выше, тем сильнее модель проявит свои признаки. В командах для Yes Ai Bot весовой коэффициент указывается после номера модели, например: <lora:1938784:1.2> ...здесь число "1.2" — это весовой коэффициент, влияющий на силу модели с номером 1938784. Как уже было отмечено ранее, весовой коэффициент обычно варьируется в диапазоне от 0.7 до 1.5, но тут нет строгих правил, т.к. некоторые авторы при обучении LoRA могут использовать иные значения. По этой причине следует обратить внимание на две вещи: описание модели в карточке на сайте Civitai - иногда авторы указывают диапазоны изменения весовых коэффициентов; примеры генераций, сделанных автором (они также видны в карточках моделей). В описании картинок есть промты, а в промтах иногда указан вес моделей Лора. Если в карточке модели ничего полезного не нашли, то смело ставьте вес равный единице и тестируйте, тестируйте, тестируйте... ведь качественный результат вы, так или иначе, получите не сразу, а лишь спустя какое-то количество итераций (повторений). Если вес, равный единице не дал ожидаемых результатов, увеличьте или уменьшите его, в зависимости от полученных ранее генераций. ...НЕ мечтайте, что все начнет получаться с первых попыток, нейросети так не работают. Хотите упростить себе жизнь и получить проверенные промты? Тогда можно направиться в галерею на нашем форуме, там размещено множество примеров настроек и промтов для нейросети Qwen Images. Будем считать, что вопрос с простыми генерациями по промтам и с моделями LoRA мы разобрали, но, если у вас остались вопросы, задайте их в Телеграм: https://t.me/yes_ai_talk Следующая важная статья — использование функций нейросети Qwen Images, в которой мы разберем полезные штуки вроде удаления фона, стилизации и работы с референсами. Настоятельно рекомендуем к ознакомлению: https://forum.yesai.su/topic/3056-neyroset-qwen-obrabotka-izobrazheniy-stilizaciya-udalenie-fona-restavraciya/
-
- 1
-
-
- images
- генерация картинок
- (и ещё 3 )
-
1. на будущее просьба размещать пожелания в разделе пожеланий (ваш топик мы уже перенесли сами) 2. мы учтем ваше пожелание, но хотим обратить внимание, что там уже есть бонус за пополнения - в течение часа после покупки любого количества монет вам предоставляется скидка на следующую покупку монет - так что вы уже можете экономить, просто делая по две покупки монет подряд
-
Нуждаюсь в советах и помощи
admin ответил Marina_Shumi вопрос в Вопросы о нейросетях и ответы на них
вы хотите чтобы нейросеть создавала чертежи по описанию ? это очень непростая задача, ибо нейронки работают в большей степени с более абстрактными задачами. ну или вам следует более подробно описать суть задачи с примерами -
veo 3 Как сделать вертикальное (портретное) видео 9:16 в Veo 3
admin опубликовал тема в Нейросети для Видео
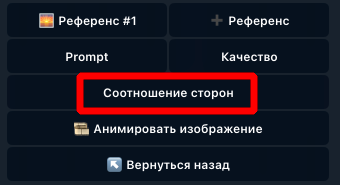
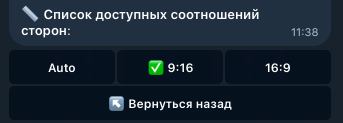
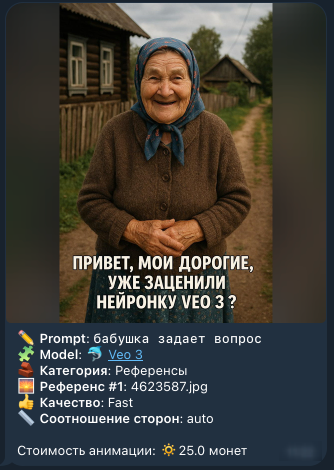
В Veo 3 можно сделать вертикальное видео 9:16: нейросеть поддерживает портретный формат и позволяет генерировать ролики для TikTok, Shorts и других мобильных платформ. При этом сохраняются и другие возможности — использование стартового кадра, озвучка текста из промта, озвучка текста из титров и другие функции. Поддержка формата 9:16 в Veo 3 появилась 9 сентября 2025 года. До недавнего времени Veo 3 умела генерировать только видео в горизонтальном формате 16:9, что подходило для YouTube, RuTube и других подобных платформ. Однако для TikTok, Shorts и просмотра со смартфона такой формат подходит хуже, чем вертикальное видео 9:16. Поэтому пользователям приходилось использовать сторонние нейросети и сервисы, чтобы преобразовывать горизонтальные ролики в вертикальные. Теперь Veo 3 нативно поддерживает генерацию видео как в формате 9:16, так и в формате 16:9. 💡 В конце статьи также покажем полезную функцию Veo 3 для озвучки текста, но сначала разберем, как сделать вертикальное видео 9:16. Как сделать вертикальное видео 9:16 в Veo 3 Разберем эту возможность на примере Yes Ai Bot: Откройте раздел Yes Video в Телеграм-боте @yes_ai_bot Отправьте боту промт или изображение вместе с промтом. Также можно загрузить сразу две картинки: в этом случае первая будет использована как стартовый кадр, а вторая — как финальный. В появившемся меню выберите нейросеть "🐬 Veo 3"; Нажмите кнопку «Соотношение сторон» и выберите нужный формат видео: Auto (автоматический режим), 16:9 (горизонтальный формат) или 9:16 (вертикальный формат). Чтобы сделать вертикальное видео в Veo 3, выберите 9:16.* * "Auto" — автоматический режим, выбранный по умолчанию. Если вы загрузите квадратный или горизонтальный референс, Veo 3 создаст видео в формате 16:9. Если загрузите вертикальный референс, нейросеть сгенерирует видео в формате 9:16. Если запускать генерацию без референса, по умолчанию получится видео 16:9. При необходимости задайте дополнительные настройки и запустите генерацию. А теперь — еще одна полезная функция Veo 3: озвучка текста из субтитров. Как озвучить текст из субтитров в Veo 3 Одна из неочевидных функций Veo 3 — распознавание текста на изображении, загруженном в качестве референса. Если добавить стартовый кадр с фотографией человека и текстом на изображении, нейросеть сможет использовать этот текст как субтитры и автоматически выполнит следующие действия: Прочтет текст, написанный на фотографии. Поймет, на каком языке он написан (поддерживаются разные языки). Поймет, какого возраста и пола персонаж, изображенный на фото. Если на референсе изображен не человек, а робот, мультяшный персонаж или кто-то иной, то голос будет автоматически подобран с подходящей тональностью. Озвучит текст из субтитров соответствующим голосом на нужном языке. ⚠️ Обратите внимание: чтобы Veo 3 озвучила текст из субтитров, нужно добавить промт к генерации. Например, можно написать: «человек говорит» или «человек поет песню», если вы хотите, чтобы персонаж не просто прочитал текст, а пропел его. Эта функция особенно полезна для блогов, видеоинструкций и массовой генерации контента для социальных сетей. С ее помощью можно быстро создавать ролики, в которых персонаж на фотографии озвучивает текст субтитров своим подходящим голосом. Вот пример такой генерации, исходное изображение на скриншоте: Результат озвучки субтитров: subtitles_audio_veo3.mp4 Рекомендуем также ознакомиться с другими статьями про Veo 3 — в них подробно разобраны дополнительные возможности нейросети: Базовые инструкции по использованию Veo 3 Как создавать длинные видео, с сохранением образов персонажей
-
Да, можно. Выбирайте в методах оплаты "Карты РФ"
-
qwen Ленин с пионерами поет гимн Союза: праздник детства и прогрессивной эпохи. Картинка из нейронной сети Qwen images Ai
admin опубликовал изображение в галерее в Qwen Images примеры промтов
 Ленин с пионерами поет гимн Союза: праздник детства и прогрессивной эпохи - Пример работы нейросети Qwen images Ai Воодушевляющая картина эпохи советского единства и детства. На ней изображен Ленин, окруженный радостными пионерами в летнем лагере, исполняющими гимн Советскому Союзу. Атмосфера наполнена светом, прогрессом и оптимизмом, что подчеркивается обилием красного цвета – символа революции и надежды. Энергичные жесты детей, их восторженные лица и улыбка Ленина передают дух энтузиазма и сплоченности. Зеленые деревья на заднем плане создают контраст и подчеркивают гармонию между человеком и природой. Яркие красные галстуки пионерские значки и развевающиеся флаги СССР служат визуальным напоминанием об идеологии того времени. Стиль изображения выдержан в духе современного прогрессивного искусства, с использованием ярких насыщенных цветов и динамичной композицией, что придает картине современный вид. Световой эффект солнечного дня и общее праздничное настроение создают ощущение радости и беззаботности. Эта работа – ода советскому детству, патриотизму и вере в светлое будущее под мудрым руководством Ленина. По сути, это символ эпохи, запечатленный яркими красками и полным энтузиазма настроением, который вызывает ностальгию и воспоминания о времени надежд и перемен ✏️ Промт: Дедушка Ленин вместе с радостными пионерами в детском лагере поют гимн Советского Союза. Яркая, прогрессивная атмосфера, много красного цвета, энергичные жесты, восторженные лица детей, Ленин улыбается и поёт вместе с ними, вокруг зелёные деревья, пионерские галстуки, флаги СССР, стилизация под современное прогрессивное искусство, яркие, насыщенные цвета, динамичная композиция, светлый солнечный день, праздничное настроение 🧩 Нейросеть: 🐼 Qwen Images 🔨 Модель нейросети: QWEN.Basic 🔧 Сэмплер: euler 🎭 Стили: No style Этот рисунок создан нейронной сетью @yes_ai_bot
Ленин с пионерами поет гимн Союза: праздник детства и прогрессивной эпохи - Пример работы нейросети Qwen images Ai Воодушевляющая картина эпохи советского единства и детства. На ней изображен Ленин, окруженный радостными пионерами в летнем лагере, исполняющими гимн Советскому Союзу. Атмосфера наполнена светом, прогрессом и оптимизмом, что подчеркивается обилием красного цвета – символа революции и надежды. Энергичные жесты детей, их восторженные лица и улыбка Ленина передают дух энтузиазма и сплоченности. Зеленые деревья на заднем плане создают контраст и подчеркивают гармонию между человеком и природой. Яркие красные галстуки пионерские значки и развевающиеся флаги СССР служат визуальным напоминанием об идеологии того времени. Стиль изображения выдержан в духе современного прогрессивного искусства, с использованием ярких насыщенных цветов и динамичной композицией, что придает картине современный вид. Световой эффект солнечного дня и общее праздничное настроение создают ощущение радости и беззаботности. Эта работа – ода советскому детству, патриотизму и вере в светлое будущее под мудрым руководством Ленина. По сути, это символ эпохи, запечатленный яркими красками и полным энтузиазма настроением, который вызывает ностальгию и воспоминания о времени надежд и перемен ✏️ Промт: Дедушка Ленин вместе с радостными пионерами в детском лагере поют гимн Советского Союза. Яркая, прогрессивная атмосфера, много красного цвета, энергичные жесты, восторженные лица детей, Ленин улыбается и поёт вместе с ними, вокруг зелёные деревья, пионерские галстуки, флаги СССР, стилизация под современное прогрессивное искусство, яркие, насыщенные цвета, динамичная композиция, светлый солнечный день, праздничное настроение 🧩 Нейросеть: 🐼 Qwen Images 🔨 Модель нейросети: QWEN.Basic 🔧 Сэмплер: euler 🎭 Стили: No style Этот рисунок создан нейронной сетью @yes_ai_bot -
Если у вас VIP и при этом генерации были бесплатными, а потом стали платными, значит система увидела, что вы проявляете достаточно высокую активность в боте. Включается защита от злоупотреблений. Что можно сделать: подождать несколько часов. Важно: система не выдает ограничения на бесплатные генерации, если пользователь проводит в боте не все свое свободное время. Если действия человека похожи на среднестатистические, то проблем не будет. Что понимается под среднестатистическими действиями: нужно спать, нужно отвлекаться от бота, например на обеды, ужины и пр., НЕ НУЖНО использовать один аккаунт вместе с кем-то. Если же вы являетесь очень активным пользователем, то система временно ограничит бесплатные генерации. Если вы войдете в более размеренный режим использования бота, то бесплатные генерации вернутся автоматически. Если у вас VIP, и вы вообще не получаете бесплатные генерации, то проверьте, есть ли у вас хотя бы 4 активных приглашенных по реферальной ссылке. Количество активных можно узнать по команде /ref - отправьте ее боту.
-
отправьте сюда или в техподдержку @yes_ai_support исходные фотографии и скриншот настроек, которые вы делали, а также промт, которые указали в настройках
-
ОБНОВЛЕНИЕ: появилась возможность создавать видео "обнять себя маленького" с помощью функции "Elements" в нейросети Kling Ai, рекомендуем ознакомиться с описанием по этой ссылке: https://forum.yesai.su/topic/280-kling-ai-neyroset-videogenerator-dlya-animacii-izobrazheniy-v-telegram-bote/#elements
-
Это делают в Veo 3, но не всегда нейронка пропускает фотки с детьми. В промте не нужно упоминать детей, младенцев, это повысит шансы.
- 1 ответ
-
- 1
-

-
sora Изысканная индейка: праздничный шедевр для вашего стола. Генерация из нейронной сети Sora Images
admin опубликовал изображение в галерее в Sora Images примеры промтов
 Изысканная индейка: праздничный шедевр для вашего стола - Генерация в нейросети Sora Images Изысканное воплощение традиционного праздника – аппетитная индейка, ставшим настоящим произведением кулинарного искусства. Сочная птица, словно вылепленная из красного кирпича, покоится на элегантной золотой тарелке, подчеркивая ее благородство и роскошь. Сцена разворачивается на фоне теплого деревянного дубового стола, добавляющего ощутимую нотку уюта и домашнего очарования. Эта фотография – идеальное решение для меню ресторана, стремящегося продемонстрировать безупречное качество и неповторимый вкус предлагаемого блюда. Создана с использованием профессиональной фотокамеры, она отличается высокой детализацией, позволяющей рассмотреть каждую текстуру и оттенок. Идеально подобранное освещение подчеркивает объемность и аппетитность индейки, вызывая непреодолимое желание попробовать это восхитительное угощение. Это не просто фотография блюда – это визуальный гимн празднику, обещающий незабываемый гастрономический опыт для каждого гостя. Внимание к деталям и безупречное исполнение делают этот снимок настоящим украшением любого меню, привлекающим внимание и вызывающим желание заказать именно эту индейку на день благодарения. Фотография отражает атмосферу торжества и радушия, создавая ощущение тепла и уюта. Идеальный выбор для ресторанов, стремящихся предложить своим гостям не просто еду, а настоящий праздник вкуса ✏️ Промт: индейка на день благодарения из красного кирпича на золотой тарелке на деревянном дубовом столе, фотография для меню ресторана, сьемка на профессиональную фотокамеру, профессиональная фотография блюда, высокая детализация, хорошее освещение 🧩 Нейросеть: 🦋 Sora Images 🎭 Стили: Shining Картинка создана с помощью нейронной сети - Yes Ai
Изысканная индейка: праздничный шедевр для вашего стола - Генерация в нейросети Sora Images Изысканное воплощение традиционного праздника – аппетитная индейка, ставшим настоящим произведением кулинарного искусства. Сочная птица, словно вылепленная из красного кирпича, покоится на элегантной золотой тарелке, подчеркивая ее благородство и роскошь. Сцена разворачивается на фоне теплого деревянного дубового стола, добавляющего ощутимую нотку уюта и домашнего очарования. Эта фотография – идеальное решение для меню ресторана, стремящегося продемонстрировать безупречное качество и неповторимый вкус предлагаемого блюда. Создана с использованием профессиональной фотокамеры, она отличается высокой детализацией, позволяющей рассмотреть каждую текстуру и оттенок. Идеально подобранное освещение подчеркивает объемность и аппетитность индейки, вызывая непреодолимое желание попробовать это восхитительное угощение. Это не просто фотография блюда – это визуальный гимн празднику, обещающий незабываемый гастрономический опыт для каждого гостя. Внимание к деталям и безупречное исполнение делают этот снимок настоящим украшением любого меню, привлекающим внимание и вызывающим желание заказать именно эту индейку на день благодарения. Фотография отражает атмосферу торжества и радушия, создавая ощущение тепла и уюта. Идеальный выбор для ресторанов, стремящихся предложить своим гостям не просто еду, а настоящий праздник вкуса ✏️ Промт: индейка на день благодарения из красного кирпича на золотой тарелке на деревянном дубовом столе, фотография для меню ресторана, сьемка на профессиональную фотокамеру, профессиональная фотография блюда, высокая детализация, хорошее освещение 🧩 Нейросеть: 🦋 Sora Images 🎭 Стили: Shining Картинка создана с помощью нейронной сети - Yes Ai